Idézet: diegho - Dátum: 2007. aug. 4., szombat - 20:46
de már tudom, biztos azért jók mert d3d10-et tudnak...
A jelenlegi játékok patch-elt izék. Tapasztalatból mondom, hogy mediumon mennek általában a HD2600XT-n 1024ben. 8600GTS-sel kb. low-mediumban jól futnak ugyanolyan felbontáson. Amúgy sikerült azokat a grafikonokat berakni ahol rosszul szerepel az Ati.
Nekem pont a GF8 és a D3D10 viszonya kérdéses. Alapvetõen a D3D szabvány olyan méretûre nõtte ki magát, hogy nehéz megreformálni a rendszert. A D3D10 némileg megváltozott a D3D9-hez képpest, eleve az MS dönti el, hogy melyik kari D3D10-es, tehát nincs önjelölés. Ez azt a problémát volt hivatott megszüntetni, hogy minden D3D10-es VGA támogassa 100%-ig a szabványt, ugye volt egy kis ferdítás az x1000-es Radeonnál, amikor az Ati a SM3.0 legnagyobb újítását a VTF-et nem támogatta. Igazából most is baj van. Az nV és az AMD másképp képzeli el a D3D10-es gyorsítót. A Microsoft vélhetõleg a Xenoshoz hasonló képességû GPU-t képzelt el az API-jához, de az nV nem éppen ebbe az irányba lépet. Mindenesetre sokkal jobban meg kellet volna határoznia az MS-nek, hogy mit ért D3D10 gyorsító alatt, bár talán az nv is tudta, hogy milyen hardver illik az új API-hoz, csak bojkottálni akarta az AMD Xenos-ból származó elõnyét.
Az MS felfogásában minden bizonnyal az R600 az a 3D-s gyorsító amit elképzelt az új API igényeihez. A probléma, hogy az R600-ra jellemzõ irányelvekkel jelenleg ezt a teljesítményt lehet elérni (plusz optimalizált driver rutinok amik még tényleg gyerekcipõben járnak, fõleg D3D10-ben). Ha az nV annó egy éve a G80-nal a Xenos-hoz hasonló képességû hardvert ad ki akkor elvétve verte volna a rendszer a régi x1950XTX-et és a 7950GTX-et. Ennek köszönhetõen a G80 egyfajta D3D9-D3D10 hibrid lett, belõve az életciklusát a jelenlegi idõszakra. Lényegében két rivális rendszer borzasztóan széthúz. Mondok egy példát. Olyan Shader kódot írunk amiben trigonometrikus (például sinus) függvény van. D3D9-ben az API adotságai miatt LUT (Look-Up table) texturát használunk, hogy kikeressük a megfelelõ eredményt, ehhez szükség van textura fetch-re ami igen nagy idõveszteség a memória címzése végett. D3D10-ben lehetõség van speciális utasítások elvégzésére, mint a sinus (sin). Ezt a GPU SFU egysége hajtja végre és meg is van az eredmény. Két eltérõ megoldás és a jelenlegi D3D10-es karikkal mindkettõ kivitelezhetõ. Hol itt a probléma? A LUT texturás megoldás a magas Alu:Tex arányú kialakítás végett nem nagyon fekszik majd az R600-nak. A G80-ban viszont az SFU egység jelentõsen lassabb a Stream prociknál, így az nV üdvöskéje a számolós megoldást nem szívlelné. Mi a teendõ? Vagy kiszúrunk az egyik gyártóval, vagy leprogramozzuk mindkettõ algoritmust. Az MS a D3D10-es API-val a számlálós megoldást próbálná erõltetni, hiszen a textura fetch nélkülözése miatt jelentõsen gyorsabban van eredmény.
A D3D10 legnagyobb újítása a Unified Shader. Ha megnézed a fejlõdést akkor látható, hogy a Pixel Shadert használják orba-szájba. A Vertex Shader kihasználatlan terület. Ezt annak köszönheti, hogy eddig kevés volt a karik Vertex feldolgozó képessége. A Unified kialakítással az MS azt akarta elérni, hogy minden shader típus hasonló sebességgel fusson. Egy valódi Unified Shader rendszer ugyanolyan gyorsan végez bármilyen Shader kóddal. Ez lenne a D3D10 áttörése. Homokszem a G80-nal kerül a rendszerbe. Az nv rendszere gyenge tejesítményt nyújt Vertex és fõleg Geometry Shader alatt. Többnyire a G80 problémája a késleltetésre vezethetõ vissza. Egy Shader proci ugye 8 Stream prociból áll (+ 2 darab SFU, de ez most nem lényeg), ezáltal 32-es batchekkel dolgozik Pixel számítás esetén. Ez azért jó, mert ez a batchméret lefedni a textura fetch esetében bekövetkezõ elérési idõ kiesését, és a Dynamic Branching hatékonysága is megfelelõ. Vertex Shader esetén 16-os batcheket számol, elméletileg azért, mert kevés a cache mérete egy futószalagon belül. A kicsi a batchnél érezteti hatását a elérési idõ kiesése. De mivel a mai programok nagyon kevés vertex Shader kódot tartalmaznak így a problémát kompenzálja a Fragment számítás gyorsasága. Sajna Geometry Shader esetén is a cache mérete lehet a probléma csak itt jóval több adatot kell elhelyezni, így jobban érezteti a hatását. Ennek a kompenzálására nagyon kicsi tömbökkel operál a rendszer, mivel így fér bele a szûkös memóriába. Azonban a kis batch duplán visszaüt, hiszen az elérési idõ nem lesz lefedve, így a számítás az adat megérkezéséig szünetel. Látható, hogy részecske alapú GS-nél még úgy ahogy jól mûködik a G80, de egy nagyméretõ Vertex tömböt kap nem megy neki normális sebességgel a számítás. Nagyon erdekes az AMD megoldása a GS feladatokra, az R600-ban. A Shader feldolgozók mellett elhelyezett egy Memory Read/Write Cache-t, azoknak az adatoknak amik idõlegesek és nem mennek tovább a ROP egységeknek.
Lényegében minden D3D generáció váltás új elképzeléseket szül. Ezek akkor jók ha fokozatosan lesznek bevezetve. Ilyen volt a D3D7-D3D8 áttérés. Ellenben a D3D8-D3D9 váltást némileg akadályozta az FX karik képességei. Ez sajnos nem következetesen ment végbe. Az nv tartotta a fejlesztõket addig míg ki nem jött az új szériája és utána bumm, jött a drasztikus teljesítményesés. Persze ez csak az FX tulajokat érintette rosszul. Akkor is kivolt kövezve egy út amit az MS és a fejlesztõk elképzeltek, de csak késõbb tudták alkalmazni. Most is van biztosan elképzelés a jövõ megoldásairól. Az egyik véglet az, hogy maradnak a jelenlegi megoldások és a jelenleg mutatott teljesítmény lesz mérvadó. A másik véglet, hogy elmennek a fejlesztõk ténylegesen a D3D10 elképzeléseinek az irányába és a G8x teljesítménye drasztikusan visszaesik, mint anno az FX-nél.
Szvsz nem rossz kari a GF8, de a HD2000-eknek felépítésbeli elõnyük van, késõbb jöttek ki, és így jobban látták az AMD-nél mi kell a jövõ játékainak.
Az x1000-eket pedig már a megjelenésükkor sem ajánlottam. Nem támogat VTF-et, pár DST mintát, és PCF-et.

Szerkesztette: Abu85 2007. 08. 05. 12:40 -kor
 Súgó
Súgó

 A téma zárva.
A téma zárva.



 kb 3 perc volt összeírni a két konfigot ennek a két kiskernek az árai alapján és nem ismeretlen a kiskerár mivel kiskerben dolgozom
kb 3 perc volt összeírni a két konfigot ennek a két kiskernek az árai alapján és nem ismeretlen a kiskerár mivel kiskerben dolgozom 











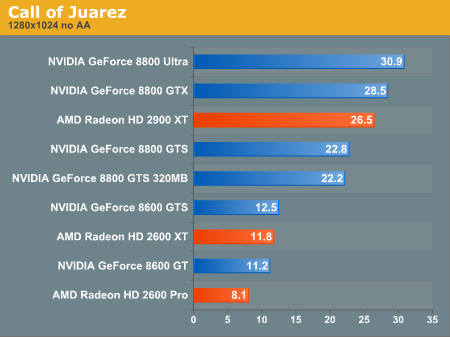
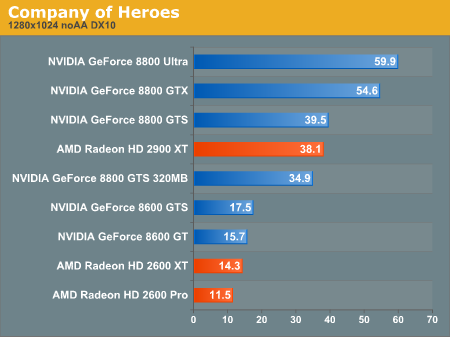
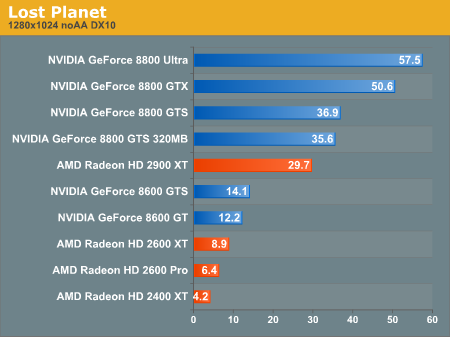

 :Ð
:Ð  de ha most kell valakinek valami akkor inkább x1950pro mint egy szaros 8600gt a siralmas teljesítményével meg a d3d10 matricával.
de ha most kell valakinek valami akkor inkább x1950pro mint egy szaros 8600gt a siralmas teljesítményével meg a d3d10 matricával.








